Aquí te presento mi primera incursión como video blogger. La he compartido aquí, porque creo que puede ser muy interesante, debido a los productos sobre los que se va a hablar, principalmente Wireless.
Ya me dejarán su feedback.

Técnico Superior en Administración de Sistemas Informáticos en Red
30 marzo 2015
19 febrero 2015
Configuración del firewall en Linux con IPtables

Un firewall es un dispositivo, ya sea software o hardware, que filtra todo el tráfico de red. El sistema operativo Linux dispone de un firewall llamado IPtables.
Iptables es un firewall incluido en el kernel de Linux desde la versión 2.4 que está incluido en el sistema operativo. Es un firewall basado en reglas, su funcionamiento se basa en aplicar reglas que el mismo firewall ejecute. Estas IPtables también se encuentran en los firmwares basados en Linux y por supuesto, los dispositivos Android.
El uso de IPtables es bastante complejo, por lo que vamos a hacer un vistazo general sobre sus opciones:
Para Iniciar/Parar/Reiniciar Iptables debemos ejecutar estos comandos:
- sudo service iptables start
- sudo service iptables stop
- sudo service iptables restart
Los principales comandos de IPtables son los siguientes (argumentos de una orden):
- -A –append → agrega una regla a una cadena.
- -D –delete → borra una regla de una cadena especificada.
- -R –replace → reemplaza una regla.
- -I –insert → inserta una regla en lugar de una cadena.
- -L –list → muestra las reglas que le pasamos como argumento.
- -F –flush → borra todas las reglas de una cadena.
- -Z –zero → pone a cero todos los contadores de una cadena.
- -N –new-chain → permite al usuario crear su propia cadena.
- -X –delete-chain → borra la cadena especificada.
- -P –policy → explica al kernel qué hacer con los paquetes que no coincidan con ninguna regla.
- -E –rename-chain → cambia el orden de una cadena.
Condiciones principales para Iptables:
- -p –protocol → la regla se aplica a un protocolo.
- -s –src –source → la regla se aplica a una IP de origen.
- -d –dst –destination → la regla se aplica a una Ip de destino.
- -i –in-interface → la regla de aplica a una interfaz de origen, como eth0.
- -o –out-interface → la regla se aplica a una interfaz de destino.
Condiciones TCP/UDP
- -sport –source-port → selecciona o excluye puertos de un determinado puerto de origen.
- -dport –destination-port → selecciona o excluye puertos de un determinado puerto de destino.
Existen muchas mas condiciones para una configuración avanzada del firewall, pero las elementales ya las tenemos listadas.
Configurar reglas por defecto
La configuración por defecto de un firewall debería ser, traducido al español, “bloquear todo excepto [reglas]“. Para configurar el firewall para que bloquee todas las conexiones debemos teclear:
- iptables -P INPUT DROP
- iptables -P FORWARD DROP
- iptables -P OUTPUT DROP
Con esto nos quedaremos sin internet, por lo que a continuación debemos empezar a crear reglas permisivas.
Para aplicar una regla que filtre un determinado puerto, debemos ejecutar:
- iptables -A INPUT -p tcp –sport 22 22 → crea una regla para el puerto de origen tcp 2222
Para bloquear el tráfico procedente de una determinada IP, debemos ejecutar:
- iptables -A INPUT -p tcp -m iprange –src-range 192.168.1.13-192.168.2.19 (ejemplo de IP)
También podriamos bloquear por MAC con la condición –mac-source.
- iptables -A INPUT -m mac –mac-source 00:00:00:00:00:01
Una vez ejecutadas las reglas que queramos aplicar, debemos guardarlas tecleando sudo service iptables save
Ver el estado del firewall
- iptables -L -n -v
El parámetro L muestra las líneas abiertas. V permite recibir más información sobre las conexiones y N nos devuelve las direcciones IP y sus correspondientes puertos sin pasar por un servidor DNS.
Eliminar las reglas existentes
Para borrar toda la configuración del firewall para volver a configurarlo de nuevo debemos teclear:
- iptables -F
Permitir conexiones entrantes
Teclearemos los siguientes parámetros:
- iptables -A INPUT -i [interface] -p [protocolo] –dport [puerto] -m state –state NEW,ESTABLISHED -j ACCEPT
-i: debemos configurar la interfaz, por ejemplo, eth0. Esto es útil en caso de tener varias tarjetas de red, si tenemos sólo una, no tenemos por qué especificar este parámetro.
-p: protocolo. Debemos especificar si el protocolo será TCP o UDP.
–dport: el puerto que queremos permitir, por ejemplo, en caso de HTTP sería el 80.
Un ejemplo para permitir las conexiones entrantes desde páginas web:
- iptables -A INPUT -i eth0 -p tcp –dport 80 -m state –state NEW,ESTABLISHED -j ACCEPT
Permitir las conexiones salientes
- iptables -A OUTPUT -o [interfaz] -p [protocolo] –sport [puerto] -m state –state ESTABLISHED -j ACCEPT
-o: debemos configurar la interfaz, por ejemplo, eth0, al igual que en el caso anterior.
-p: protocolo. Debemos especificar si el protocolo será TCP o UDP.
–sport: el puerto que queremos permitir, por ejemplo, en caso de HTTPS sería el 443.
Un ejemplo para permitir el tráfico saliente hacia páginas web:
- iptables -A OUTPUT -o eth0 -p tcp –sport 80 -m state –state ESTABLISHED -j ACCEPT
Permitir los paquetes ICMP
Por defecto, el ping está deshabilitado. Debemos habilitarlo manualmente añadiendo las correspondientes entradas en iptables. Para ello teclearemos:
Para poder hacer ping a otros servidores:
- iptables -A OUTPUT -p icmp –icmp-type echo-request -j ACCEPT
Para permitir recibir solicitudes de ping de otros equipos:
- iptables -A INPUT -p icmp –icmp-type echo-reply -j ACCEPT
Permitir que el tráfico interno salga a internet
En el caso de tener 2 tarjetas de red (eth0 en local y eth1 conectada a internet) podemos configurar el firewall para que reenvíe el tráfico de la red local a través de internet. Para ello escribiremos:
- iptables -A FORWARD -i eth0 -o eth1 -j ACCEPT
Bloquear y prevenir ataques DDoS
- iptables -A INPUT -p tcp –dport 80 -m limit –limit 25/minute –limit-burst 100 -j ACCEPT
Consultar los paquetes rechazados por iptables
Para saber los paquetes que iptables ha rechazado debemos teclear:
- iptables -N LOGGING
Ejemplos prácticos:
Cómo bloquear las conexiones entrantes por el puerto 1234:
- iptables -A INPUT -p tcp –dport 1234 -j DROP
- iptables -A INPUT -i eth1 -p tcp –dport 80 -j DROP → bloquea en la interfaz eth1
Bloquear una dirección IP:
- iptables -A INPUT -s 192.168.0.0/24 -j DROP
Bloquear una dirección IP de salida:
- iptables -A OUTPUT -d 75.126.153.206 -j DROP
También podemos bloquear una url, por ejemplo, facebook:
- iptables -A OUTPUT -p tcp -d www.facebook.com -j DROP
Bloquear el tráfico desde una direccion MAC:
- iptables -A INPUT -m mac –mac-source 00:0F:EA:91:04:08 -j DROP
Bloquear peticiones ping:
- iptables -A INPUT -p icmp –icmp-type echo-request -j DROP
UFW (Uncomplicated Firewall) es una herramienta de configuración de firewall para Ubuntu desde la consola, desarrollado para facilitar la configuración del firewall Iptables. Ufw proporciona una manera fácil de crear un firewall basado en host IPv4 o IPv6.
Lo primero que debemos hacer es instalar ufw desde apt-get con:
- sudo apt-get install ufw
Ahora ejecutamos el firewall tecleando sudo ufw enable. Para parar el firewall, teclearemos sudo ufw disable, y para reiniciarlo, primero lo pararemos y a continuación lo volveremos a arrancar con los comandos especificados.
Una vez tengamos el firewall funcionando, ya podemos comenzar a establecer reglas en su funcionamiento. Para aplicar una regla que permita por defecto todo el tráfico, tecleamos:
- sudo ufw default allow
Por el contrario, para bloquear todo el tráfico, teclearemos:
- sudo ufw default deny
Para aplicar reglas a determinados puertos, lo haremos mediante el comando:
- sudo ufw allow\deny [puerto]/[protocolo]
Ejemplo:
- sudo ufw allow 1234/tcp (permite las conexiones del puerto 1234 en tcp)
- sudo ufw deny 4321/udp (bloquea las conexiones del puerto 4321 en udp)
Existe un archivo que contiene más reglas predefinidas en la ruta /etc/ufw/before.rules donde, por ejemplo, podemos permitir o bloquear el ping externo. Para ello, pondremos una # delante de la linea -A ufw-before-input -p icmp –icmp-type echo-request -j ACCEPT
Podemos consultar las reglas del firewall desde un terminal tecleando sudo ufw status
Como podemos ver, con UFW es bastante sencillo gestionar a nivel ipv4 e ipv6 nuestro firewall iptables. Todo ello podemos gestionarlo desde un terminal sin necesidad de disponer de una interfaz gráfica, pero aún podemos facilitarlo más con otra aplicación, llamada gufw, que es una interfaz gráfica para ufw que simplifica aún más su uso.
Para instalar gufw debemos escribir en un terminal sudo apt-get install gufw
Una vez instalado, lo ejecutamos escribiendo gufw o buscándolo en el panel de aplicaciones.
La primera ventana que nos muestra el programa nos permite activar y desactivar el firewall, establecer reglas por defecto para el tráfico entrante y saliente (permitir, rechazar y denegar), y, en la parte inferior, crear reglas.

Si pulsamos en el botón + de la parte inferior, accedemos al menú de configuración de reglas. Aqui podemos añadir reglas personalizadas en cuanto a puertos, aplicaciones, ips de origen, etc.

Para añadir una regla por puerto igual que hemos especificado desde terminal, seleccionamos si queremos permitir (allow) o bloquear (deny), si queremos que se filtre el tráfico entrante o saliente, el protocolo, ya sea tcp o udp y el puerto a filtrar.
Las posibilidades de iptables son prácticamente infinitas, y la dificultad de configuración aumenta exponencialmente según sean de complejas las configuraciones que queremos realizar. Desde RedesZone esperamos que con este pequeño tutorial podáis configurar vuestro firewall iptables a nivel básico de forma sencilla.
17 febrero 2015
Cómo activar la verificación en dos pasos para acceder a tu PC con Linux
Activar la verificación en dos pasos en Linux es una de las mejores formas de mejorar la seguridad, incluso robando nuestra contraseña nadie tendrá la capacidad de entrar a nuestro PC si no posee nuestro smartphone.
Articulo de Ander Raso en Hipertextual

A estas alturas todos sabemos que usar la misma contraseña en multitud de sitios diferentes es un grave fallo de seguridad. Si dicha contraseña es robada, un atacante podría tener acceso a todo lo que hayamos protegido con esa clave. Sin embargo, llevar la cuenta de todas esas contraseñas distintas que hagamos puede ser realmente difícil, necesitando al final ayudas como programas que nos las organicen. Muchos de estos organizadores de claves a su vez, necesitan de una contraseña maestra, la cual, si es robada concede acceso a las demás claves.
Para proteger nuestras cuentas existen otros métodos que ofrecen un paso de seguridad extra, como por ejemplo la verificación en dos pasos. Este método es muy sencillo, pues solo se necesitan dos cosas diferentes. La primera es algo que sabemos, nuestra contraseña y lo segundo es algo que tenemos, nuestro smartphone. Con la verificación en dos pasos, para entrar a nuestra cuenta tendremos que usar un usuario y contraseña, pero después nos pedirá una clave de verificación aleatoria que conseguiremos de nuestro teléfono. Por lo tanto, para que alguien entre en una cuenta nuestra no le valdrá con saber la contraseña de la cuenta, porque también necesitará nuestro teléfono para ingresar una clave de verificación que además está constantemente en cambio.
En este artículo, vamos a usar el servicio de verificación en dos pasos que proporciona Google para fortalecer la seguridad de nuestro usuario en un sistema Linux. El resultado final será una cuenta a la que después de ingresar nuestro usuario y contraseña, nos pedirá una clave de verificación que se generará en nuestro smartphone y que cambiará cada treinta segundos.
Paso 1: Instalar las herramientas necesarias
Los pasos de está guía han sido realizados en la distribución Ubuntu 14.10, en un entorno Unity con el administrador de sesiones LightDM, pero los principios son aplicables para otras distribuciones.
En el PC: Google Authenticator PAM
Lo primero que debemos hacer es abrir una terminal y ejecutar el comando de instalación (para otras distros puede que tenga un nombre diferente):
$ sudo apt-get install libpam-google-authenticator
En el smartphone: Google Authenticator (u otra que haga una función similar)
Instalamos Google Authenticator desde Google Play si estamos en Android. También está disponible para iOS.
Paso 2: Configurar la verificación en dos pasos en Linux
En el ordenador:

Para conseguir mejorar la seguridad con la verificación en dos pasos en Linux, haremos una clave secreta, a partir de la cual nuestro smartphone creará las claves de verificación que nuestro PC pedirá al hacer login. Para ello, en una terminal ejecutaremos el siguiente comando:
$ google-authenticator
Nos pregunatará si queremos que las claves de verificación estén basadas en el tiempo, contestaremos que sí con y. Lo que veremos ahora será un código QR que nuestro smartphone podrá reconocer vía Google Authenticator. También podemos introducir la clave secreta directamente en la aplicación, es la que pone your new secret is: clave. En este punto, nos da una serie de códigos de emergencia por si no llevamos el móvil encima, que sería conveniente tenerlos a mano por si las moscas. También nos dará más opciones sobre las claves de identificación, a las que contestaremos con y o n dependiendo de nuestras preferencias personales.
Ahora debemos abrir el archivo de configuración del administrador de sesiones LightDM:
sudo gedit /etc/pam.d/lightdm
Al final del archivo añadiremos la siguiente línea:
auth required pam_google_authenticator.so nullok

Guardamos el archivo y la próxima vez que iniciemos sesión comprobaremos que nos pide una clave de verificación. El nullok es para que los usuarios que no hayan configurado la verificación puedan entrar normalmente a su sesión.
En el móvil:
Necesitamos el teléfono para que nos cree las claves de verificación. Una vez añadida a Google Authenticator la clave secreta creada en el paso anterior vía código QR o manualmente, le pondremos el nombre que queramos a esta nueva cuenta y seleccionaremos la opción "basada en el tiempo". Ahora en nuestro teléfono veremos como cada 30 segundos va cambiando la clave de verificación para nuestro PC.

Con esto la tenemos una verificación en dos pasos en Linux. Si un día queremos retirar esta verificación, solo tendremos que borrar la línea que añadimos al archivo /etc/pam.d/lightdm.
05 octubre 2014
¿Qué es un Agente Relay de DHCP?
Agentes Relay de DHCP.
Hasta ahora, por lo que hemos visto del funcionamiento de DHCP, se necesita que haya al menos un servidor DHCP en cada red en la que existan clientes DHCP. Pero, si una organización ha estructurado su red informática en varias subredes con clientes DHCP, ¿No crees que sería excesivo tener en funcionamiento servidores DHCP en todas las subredes? ¿Podría tenerse un servidor DHCP que centralizase el servicio para todas las subredes?
Pues efectivamente se puede centralizar el servicio DHCP y hacer que un solo servidor proporcione automáticamente IP a clientes de varias redes. Para realizar esto, hay que utilizar agentes relay.
Un agente relay DHCP es un dispositivo de la red que escucha las peticiones DHCP que se producen en la red, y las encamina hacia un servidor DHCP que se encuentra en otra red para que éste las atienda. El servidor DHCP dará una respuesta que enviará hacia el agente relay y éste la trasladará al cliente que hizo la petición.
Generalmente el agente relay estará implementado en un router, el cual realiza el encaminamiento entre la red con clientes DHCP y la red en la que se encuentra el servidor DHCP. Si la organización tiene varias redes, puede tener varios agentes relay y un solo servidor DHCP centralizado. También es posible implementar el agente relay en ordenadores con varios adaptadores de red que hagan funciones de encaminamiento entre cada una de las redes a las que pertenecen.
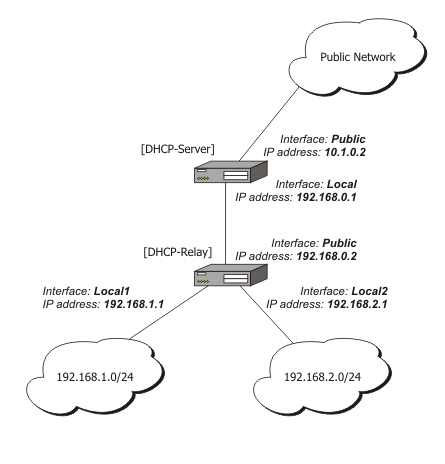
La Imagen muestra como un mensaje de difusión DHCP (DHCP_DISCOVER) se envía a través de un router que actúa como agente relay hacia un servidor DHCP. El mensaje parte de un ordenador de una red local y se señala con una flecha de origen, llega a todos los ordenadores del la red y al router y se señala con flechas destino, el router es un agente relay y reenvía la solicitud DHCP hacia un ordenador servidor DHCP que está fuera de la red local.
El funcionamiento y características de los agentes relay se establece en el RFC 1542. Para que un router pueda ser agente relay es necesario, por tanto, que cumpla el estándar RFC 1542.
Para configurar un agente relay. Es necesario:
Hasta ahora, por lo que hemos visto del funcionamiento de DHCP, se necesita que haya al menos un servidor DHCP en cada red en la que existan clientes DHCP. Pero, si una organización ha estructurado su red informática en varias subredes con clientes DHCP, ¿No crees que sería excesivo tener en funcionamiento servidores DHCP en todas las subredes? ¿Podría tenerse un servidor DHCP que centralizase el servicio para todas las subredes?
Pues efectivamente se puede centralizar el servicio DHCP y hacer que un solo servidor proporcione automáticamente IP a clientes de varias redes. Para realizar esto, hay que utilizar agentes relay.
Un agente relay DHCP es un dispositivo de la red que escucha las peticiones DHCP que se producen en la red, y las encamina hacia un servidor DHCP que se encuentra en otra red para que éste las atienda. El servidor DHCP dará una respuesta que enviará hacia el agente relay y éste la trasladará al cliente que hizo la petición.
Generalmente el agente relay estará implementado en un router, el cual realiza el encaminamiento entre la red con clientes DHCP y la red en la que se encuentra el servidor DHCP. Si la organización tiene varias redes, puede tener varios agentes relay y un solo servidor DHCP centralizado. También es posible implementar el agente relay en ordenadores con varios adaptadores de red que hagan funciones de encaminamiento entre cada una de las redes a las que pertenecen.
La Imagen muestra como un mensaje de difusión DHCP (DHCP_DISCOVER) se envía a través de un router que actúa como agente relay hacia un servidor DHCP. El mensaje parte de un ordenador de una red local y se señala con una flecha de origen, llega a todos los ordenadores del la red y al router y se señala con flechas destino, el router es un agente relay y reenvía la solicitud DHCP hacia un ordenador servidor DHCP que está fuera de la red local.
El funcionamiento y características de los agentes relay se establece en el RFC 1542. Para que un router pueda ser agente relay es necesario, por tanto, que cumpla el estándar RFC 1542.
Para configurar un agente relay. Es necesario:
- Activar el agente relay en el dispositivo de encaminamiento.
- Indicar en el agente relay cual es la red cliente.
- Indicar en el agente relay cual es el servidor DHCP que va a atender las peticiones DHCP.
- En el servidor DHCP centralizado debemos configurar varias subredes a las que se da el servicio indicando las direcciones IP que se van a otorgar dentro de cada subred. Más adelante, en esta misma unidad se detallará como se configuran subredes clientes en los servidores DHCP.
21 agosto 2014
¿Qué es MPLS?
El término MPLS (Conmutación de etiquetas multiprotocolo) representa un conjunto de especificaciones definidas por el IETF (Grupo de Trabajo de Ingeniería de Internet) que le asigna a las tramas que circulan por la red una identificación que le indique a los routers la ruta que deben seguir los datos. Por lo tanto, MPLS sirve para la administración de la calidad de servicio al definir 5 clases de servicios, conocidos como CoS.
- Video. La clase de servicio para transportar video tiene un nivel de prioridad más alto que las clases de servicio para datos.
- Voz. La clase de servicio para transportar voz tiene un nivel de prioridad equivalente al de video, es decir, más alto que las clases de servicio para datos.
- Datos de alta prioridad (D1). Ésta es la clase de servicio con el nivel de prioridad más alto para datos. Se utiliza particularmente para aplicaciones que son críticas en cuanto necesidad de rendimiento, disponibilidad y ancho de banda.
- Datos de prioridad (D2). Esta clase de servicio se relaciona con aplicaciones que no son críticas y que tienen requisitos particulares en cuanto a ancho de banda.
- Los datos no prioritarios (D3) representan la clase de servicio de prioridad más baja.
Las especificaciones de MPLS operan en la capa 2 del modelo OSI y pueden funcionar particularmente en redes IP, ATM o frame relay.
16 junio 2014
Linux para novatos: 10 comandos para obtener información del sistema

No necesitas una herramienta gráfica para ver el estado actual de tu ordenador. Aprende con estos comandos para obtener información del sistema cómo hacerlo desde la terminal.
Anteriormente les habíamos dado algunos comandos básicos para usar la terminal. Ahora que tienes una pequeña idea de como utilizarla, te presentamos 10 comandos muy útiles para obtener información de tu sistema Linux sin recurrir a herramientas con interfaz gráfica.
Htop
Htop es una herramienta para administrar los procesos del sistema de manera interactiva. Por defecto no viene incluido en nuestro sistema, para instalarlo en Arch Linux:
# pacman -S htop Para instalarlo en Ubuntu y distribuciones derivadas:
$ sudo apt-get install htop Una vez instalado podemos ejecutarlo de la siguiente forma:
$ htop Una vez invocado muestra un listado de los procesos que están actualmente en ejecución en todo el sistema; estos se van actualizando en tiempo real ordenados por consumo de CPU. Entre otras utilidades podemos ver el pid de un proceso, su usuario y el porcentaje de uso de procesador y memoria, entre otras.
Lspci
El comando lspci lista todos los buses PCI y muestra los detalles acerca de los dispositivos conectados a ellos. Por ejemplo, el adaptador VGA, la tarjeta gráfica, el adaptador de red, los puertos USB y controladores SATA.Para ejecutarlo, hacemos:
$ lspci lsusb
Este comando muestra todos los puertos USB y los detalles acerca de los dispositivos conectados a ellos. Para ver su salida solo debemos ejecutar:
$ lsusb La información que imprime el comando por defecto es general, si deseas ver detalles sobre cada puerto puedes utilizar la opción verbose -v.
Df
Df es un comando muy útil que muestra un informe de las particiones del sistema y sus puntos de montaje, así como el espacio utilizado y disponible en cada una. Es muy fácil de utilizar, simplemente ejecutamos:
$ df Para sustituir la columna de bloques por el tamaño en Mb o Gb según sea el caso, utilizamos la opción:
-h.
Fdisk
Fdisk es un gestor de particiones. Nos permite modificar las particiones en los discos duros pero también se puede utilizar para enumerar la información de la partición así como su cantidad de bloques y sistema de archivos. Su sintaxis es:
$ fdisk [options] Para invocarlo deben utilizar la opción sudo si la tienen habilitada, de lo contrario deben autenticarse como root o superusuario. La opción que nos atañe es -l, que lista los tipos de partición. Entonces, para ver la lista de particiones de nuestro disco duro, sería:
# fdisk -l 
Mount
$ mount Lspcu
El comando lscpu muestra información sobre el procesador del sistema, como su velocidad, numero de núcleos y fabricante. No tiene ninguna opción o funcionalidades adicionales. Para ver su salida, hacemos:
$ lscpu Hwinfo
Hwinfo es una utilidad de propósito general que muestra información detallada sobre varios componentes de hardware tales como CPU, memoria, disco, controladores USB y adaptadores de red.Para instalarlo en Arch Linux:
# pacman -S hwinfo Para instalarlo en Ubuntu y distribuciones derivadas:
$ sudo apt-get install hwinfo Una vez instalado lo ejecutamos con:
$ hwinfo Free
Con el comando free podemos comprobar la cantidad de memoria RAM usada, ver la disponible y el total. Para usarlo, ejecutamos:
$ free Lsblk
Lsblk lista información de todos los dispositivos de bloques del sistema que son las particiones del disco duro y otros dispositivos de almacenamiento como unidades ópticas y discos duros externos. Para utilizarlo solo dejemos ejecutar:
$lsblk No esta demás recordarles usar man para obtener una documentación completa de todos los comandos que quieran probar. Por ejemplo, para ver información acerca del comando lsblk, hacemos:
$ man lsblk ¿Qué otros comandos para obtener información del sistema sueles utilizar?
Fuente: Bitelia
12 junio 2014
Modelo de Referencia OSI
El modelo de referencia OSI es el modelo principal para las comunicaciones por red. Aunque existen otros modelos, en la actualidad la mayoría de los fabricantes de redes relacionan sus productos con el modelo de referencia OSI, especialmente cuando desean enseñar a los usuarios cómo utilizar sus productos. Los fabricantes consideran que es la mejor herramienta disponible para enseñar cómo enviar y recibir datos a través de una red.
El modelo de referencia OSI permite que los usuarios vean las funciones de red que se producen en cada capa. Más importante aún, el modelo de referencia OSI es un marco que se puede utilizar para comprender cómo viaja la información a través de una red. Además, puede usar el modelo de referencia OSI para visualizar cómo la información o los paquetes de datos viajan desde los programas de aplicación (por ej., hojas de cálculo, documentos, etc.), a través de un medio de red (por ej., cables, etc.), hasta otro programa de aplicación ubicado en otro computador de la red, aún cuando el transmisor y el receptor tengan distintos tipos de medios de red.
En el modelo de referencia OSI, hay siete capas numeradas, cada una de las cuales ilustra una función de red específica. Esta división de las funciones de networking se denomina división en capas. Si la red se divide en estas siete capas, se obtienen las siguientes ventajas:
- Divide la comunicación de red en partes más pequeñas y sencillas.
- Normaliza los componentes de red para permitir el desarrollo y el soporte de los productos de diferentes fabricantes.
- Permite a los distintos tipos de hardware y software de red comunicarse entre sí.
- Impide que los cambios en una capa puedan afectar las demás capas, para que se puedan desarrollar con más rapidez.
- Divide la comunicación de red en partes más pequeñas para simplificar el aprendizaje.
Capa 7: La capa de aplicación
Capa 6: La capa de presentación
Capa 5: La capa de sesión
Capa 4: La capa de transporte
Capa 3: La capa de red
Capa 2: La capa de enlace de datos
Capa 1: La capa física

Capa 7: La capa de aplicación.
La capa de aplicación es la capa del modelo OSI más cercana al usuario; suministra servicios de red a las aplicaciones del usuario. Difiere de las demás capas debido a que no proporciona servicios a ninguna otra capa OSI, sino solamente a aplicaciones que se encuentran fuera del modelo OSI. Algunos ejemplos de aplicaciones son los programas de hojas de cálculo, de procesamiento de texto y los de las terminales bancarias. La capa de aplicación establece la disponibilidad de los potenciales socios de comunicación, sincroniza y establece acuerdos sobre los procedimientos de recuperación de errores y control de la integridad de los datos. Si desea recordar a la Capa 7 en la menor cantidad de palabras posible, piense en los navegadores de Web.
Capa 6: La capa de presentación.
La capa de presentación garantiza que la información que envía la capa de aplicación de un sistema pueda ser leída por la capa de aplicación de otro. De ser necesario, la capa de presentación traduce entre varios formatos de datos utilizando un formato común. Si desea recordar la Capa 6 en la menor cantidad de palabras posible, piense en un formato de datos común.
Capa 5: La capa de sesión.
Como su nombre lo implica, la capa de sesión establece, administra y finaliza las sesiones entre dos hosts que se están comunicando. La capa de sesión proporciona sus servicios a la capa de presentación. También sincroniza el diálogo entre las capas de presentación de los dos hosts y administra su intercambio de datos. Además de regular la sesión, la capa de sesión ofrece disposiciones para una eficiente transferencia de datos, clase de servicio y un registro de excepciones acerca de los problemas de la capa de sesión, presentación y aplicación. Si desea recordar la Capa 5 en la menor cantidad de palabras posible, piense en diálogos y conversaciones.
Capa 4: La capa de transporte.
La capa de transporte segmenta los datos originados en el host emisor y los reensambla en una corriente de datos dentro del sistema del host receptor. El límite entre la capa de transporte y la capa de sesión puede imaginarse como el límite entre los protocolos de aplicación y los protocolos de flujo de datos. Mientras que las capas de aplicación, presentación y sesión están relacionadas con asuntos de aplicaciones, las cuatro capas inferiores se encargan del transporte de datos.
La capa de transporte intenta suministrar un servicio de transporte de datos que aísla las capas superiores de los detalles de implementación del transporte. Específicamente, temas como la confiabilidad del transporte entre dos hosts es responsabilidad de la capa de transporte. Al proporcionar un servicio de comunicaciones, la capa de transporte establece, mantiene y termina adecuadamente los circuitos virtuales. Al proporcionar un servicio confiable, se utilizan dispositivos de detección y recuperación de errores de transporte. Si desea recordar a la Capa 4 en la menor cantidad de palabras posible, piense en calidad de servicio y confiabilidad.
Capa 3: La capa de red.
La capa de red es una capa compleja que proporciona conectividad y selección de ruta entre dos sistemas de hosts que pueden estar ubicados en redes geográficamente distintas. Si desea recordar la Capa 3 en la menor cantidad de palabras posible, piense en selección de ruta, direccionamiento y enrutamiento.
Capa 2: La capa de enlace de datos.
La capa de enlace de datos proporciona tránsito de datos confiable a través de un enlace físico. Al hacerlo, la capa de enlace de datos se ocupa del direccionamiento físico (comparado con el lógico) , la topología de red, el acceso a la red, la notificación de errores, entrega ordenada de tramas y control de flujo. Si desea recordar la Capa 2 en la menor cantidad de palabras posible, piense en tramas y control de acceso al medio.
Capa 1: La capa física.
La capa física define las especificaciones eléctricas, mecánicas, de procedimiento y funcionales para activar, mantener y desactivar el enlace físico entre sistemas finales. Las características tales como niveles de voltaje, temporización de cambios de voltaje, velocidad de datos físicos, distancias de transmisión máximas, conectores físicos y otros atributos similares son definidos por las especificaciones de la capa física. Si desea recordar la Capa 1 en la menor cantidad de palabras posible, piense en señales y medios.
MODELO DE REFERENCIA TCP
Aunque el modelo de referencia OSI sea universalmente reconocido, el estándar abierto de Internet desde el punto de vista histórico y técnico es el Protocolo de control de transmisión/Protocolo Internet (TCP/IP). El modelo de referencia TCP/IP y la pila de protocolo TCP/IP hacen que sea posible la comunicación entre dos computadores, desde cualquier parte del mundo, a casi la velocidad de la luz. El modelo TCP/IP tiene importancia histórica, al igual que las normas que permitieron el desarrollo de la industria telefónica, de energía eléctrica, el ferrocarril, la televisión y las industrias de vídeos.
El Departamento de Defensa de EE.UU. (DoD) creó el modelo TCP/IP porque necesitaba una red que pudiera sobrevivir ante cualquier circunstancia, incluso una guerra nuclear. Para brindar un ejemplo más amplio, supongamos que el mundo está en estado de guerra, atravesado en todas direcciones por distintos tipos de conexiones: cables, microondas, fibras ópticas y enlaces satelitales. Imaginemos entonces que se necesita que fluya la información o los datos (organizados en forma de paquetes), independientemente de la condición de cualquier nodo o red en particular de la internetwork (que en este caso podrían haber sido destruidos por la guerra). El DoD desea que sus paquetes lleguen a destino siempre, bajo cualquier condición, desde un punto determinado hasta cualquier otro. Este problema de diseño de difícil solución fue lo que llevó a la creación del modelo TCP/IP, que desde entonces se transformó en el estándar a partir del cual se desarrolló Internet.
A medida que obtenga más información acerca de las capas, tenga en cuenta el propósito original de Internet; esto le ayudará a entender por qué motivo ciertas cosas son como son. El modelo TCP/IP tiene cuatro capas: la capa de aplicación, la capa de transporte, la capa de Internety la capa de acceso de red. Es importante observar que algunas de las capas del modelo TCP/IP poseen el mismo nombre que las capas del modelo OSI. No confunda las capas de los dos modelos, porque la capa de aplicación tiene diferentes funciones en cada modelo.
EL MODELO TCP/ IP

Los diseñadores de TCP/IP sintieron que los protocolos de nivel superior deberían incluir los detalles de las capas de sesión y presentación. Simplemente crearon una capa de aplicación que maneja protocolos de alto nivel, aspectos de representación, codificación y control de diálogo. El modelo TCP/IP combina todos los aspectos relacionados con las aplicaciones en una sola capa y garantiza que estos datos estén correctamente empaquetados para la siguiente capa.
Capa de transporte.
La capa de transporte se refiere a los aspectos de calidad del servicio con respecto a la confiabilidad, el control de flujo y la corrección de errores. Uno de sus protocolos, el protocolo para el control de la transmisión (TCP), ofrece maneras flexibles y de alta calidad para crear comunicaciones de red confiables, sin problemas de flujo y con un nivel de error bajo. TCP es un protocolo orientado a la conexión. Mantiene un diálogo entre el origen y el destino mientras empaqueta la información de la capa de aplicación en unidades denominadas segmentos. Orientado a la conexión no significa que el circuito exista entre los computadores que se están comunicando (esto sería una conmutación de circuito). Significa que los segmentos de Capa 4 viajan de un lado a otro entre dos hosts para comprobar que la conexión exista lógicamente para un determinado período. Esto se conoce como conmutación de paquetes.
Capa de Internet.
El propósito de la capa de Internet es enviar paquetes origen desde cualquier red en la internetwork y que estos paquetes lleguen a su destino independientemente de la ruta y de las redes que recorrieron para llegar hasta allí. El protocolo específico que rige esta capa se denomina Protocolo Internet (IP). En esta capa se produce la determinación de la mejor ruta y la conmutación de paquetes. Esto se puede comparar con el sistema postal. Cuando envía una carta por correo, usted no sabe cómo llega a destino (existen varias rutas posibles); lo que le interesa es que la carta llegue.
Capa de acceso de red.
El nombre de esta capa es muy amplio y se presta a confusión. También se denomina capa de host a red. Es la capa que se ocupa de todos los aspectos que requiere un paquete IP para realizar realmente un enlace físico y luego realizar otro enlace físico. Esta capa incluye los detalles de tecnología LAN y WAN y todos los detalles de las capas física y de enlace de datos del modelo OSI.

- FTP: File Transfer Protocol (Protocolo de transferencia de archivos)
- HTTP: Hypertext Transfer Protocol (Protocolo de transferencia de hipertexto)
- SMTP: Simple Mail Transfer Protocol (Protocolo de transferencia de correo simple)
- DNS: Domain Name System (Sistema de nombres de dominio)
- TFTP: Trivial File Transfer Protocol (Protocolo de transferencia de archivo trivial)
En el modelo TCP/IP existe solamente un protocolo de red: el protocolo Internet, o IP, independientemente de la aplicación que solicita servicios de red o del protocolo de transporte que se utiliza. Esta es una decisión de diseño deliberada. IP sirve como protocolo universal que permite que cualquier computador en cualquier parte del mundo pueda comunicarse en cualquier momento.

Similitudes:
- Ambos se dividen en capas
- Ambos tienen capas de aplicación, aunque incluyen servicios muy distintos
- Ambos tienen capas de transporte y de red similares
- Se supone que la tecnología es de conmutación por paquetes (no de conmutación por circuito)
- Los profesionales de networking deben conocer ambos
- TCP/IP combina las funciones de la capa de presentación y de sesión en la capa de aplicación
- TCP/IP combina la capas de enlace de datos y la capa física del modelo OSI en una sola capa
- TCP/IP parece ser más simple porque tiene menos capas
- Los protocolos TCP/IP son los estándares en torno a los cuales se desarrolló la Internet, de modo que la credibilidad del modelo TCP/IP se debe en gran parte a sus protocolos. En comparación, las redes típicas no se desarrollan normalmente a partir del protocolo OSI, aunque el modelo OSI se usa como guía.
Suscribirse a:
Entradas (Atom)